Using LLMs to Generate Relevance Labels
How Promoted large language models (LLMs) learn human judgement and train semantic relevance classifiers
Conversion rates and click predictions don't necessarily correlate to a search result being semantically relevant to the query. Irrelevant results degrade the user experience and may harm the long-term success of the marketplace. Promoted uses custom large language models to help deliver relevant results to the user.
Promoted combines LLMs with expert human review to generate numeric "relevance" annotations from 1 to 5 using a domain-customizable, plain-text, human-like rubric. See Default Semantic Relevance Rubric. These labels are regularly generated on a sample of production traffic from retrieval systems to balance a mixture of irrelevant (but retrievable) insertions and typically highly relevant and delivered insertions.
These relevance labels can be used directly as features and blender trimming rules (memorization), and they can be inferred using a mixture of distribution and similarity features using features like an ensemble of embedding models, text-matching features, and other non-engagement or historical features. Inferred relevance labels are much faster and cheaper to generate than full LLM-generated labels at inference time and ensure high coverage of semantic relevance labeling not possible with memorization.
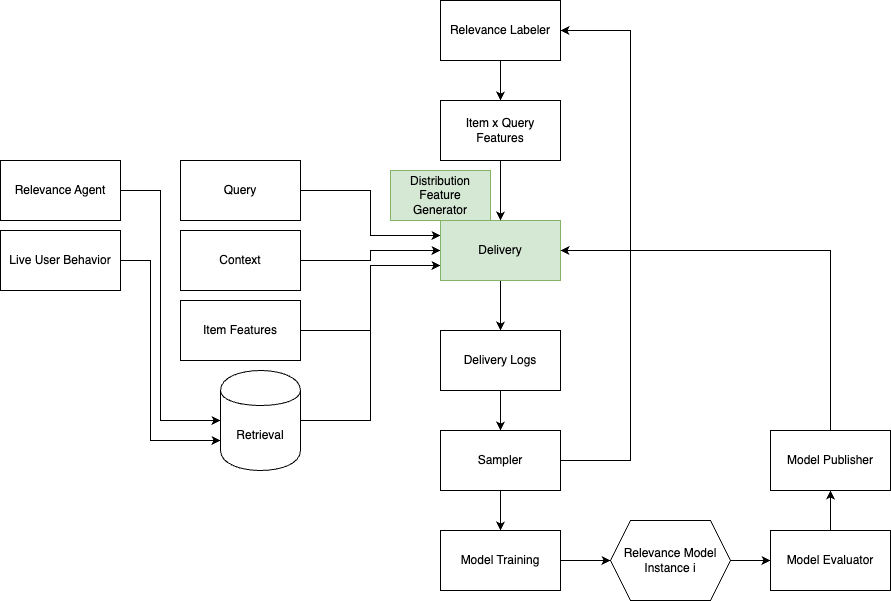
System diagram of a relevance labeler that generates supervised relevance training examples on sampled live Delivery traffic and regularly trains a relevance classifier model published using the Promoted AutoML system.
Updated 6 months ago