Delivery System Diagrams
System-level descriptions of Promoted's ML and Delivery services for engineers
View the system diagram slide deck.
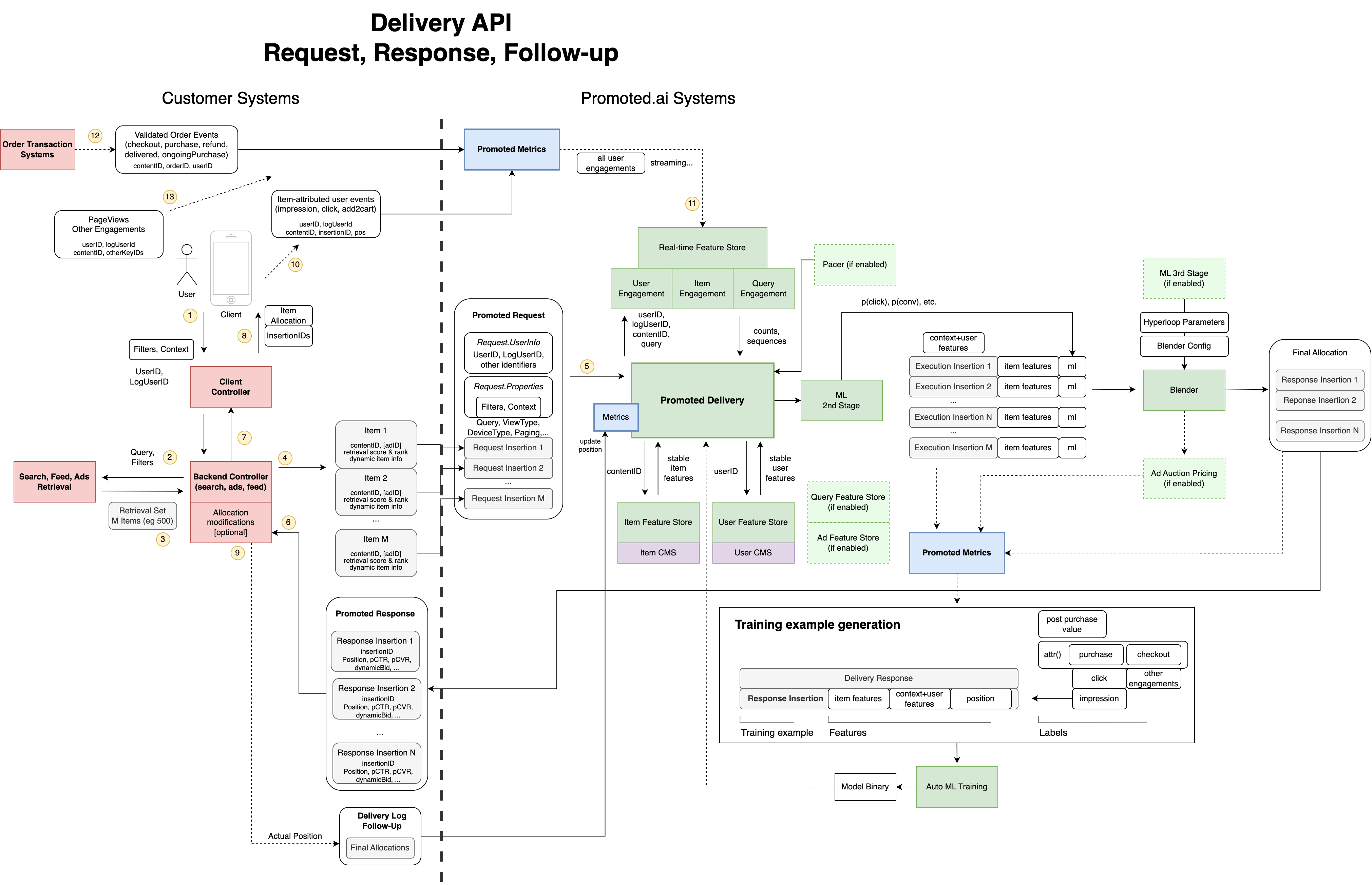
Delivery API Ads, Search, and Feed Unified Ranking
This diagram shows how Promoted.ai integrates with customer search, ads, and recommendation retrieval systems to deliver optimized listing allocations while generating training examples for ML (machine learning) and optimization. Note that both Metrics and Delivery APIs must be integrated to generate any training examples to start ML training. We use "Second stage ranking" and "third stage ranking" or "blending and allocation" with forward-filling ML training example generation. We do not backfill training examples in general.
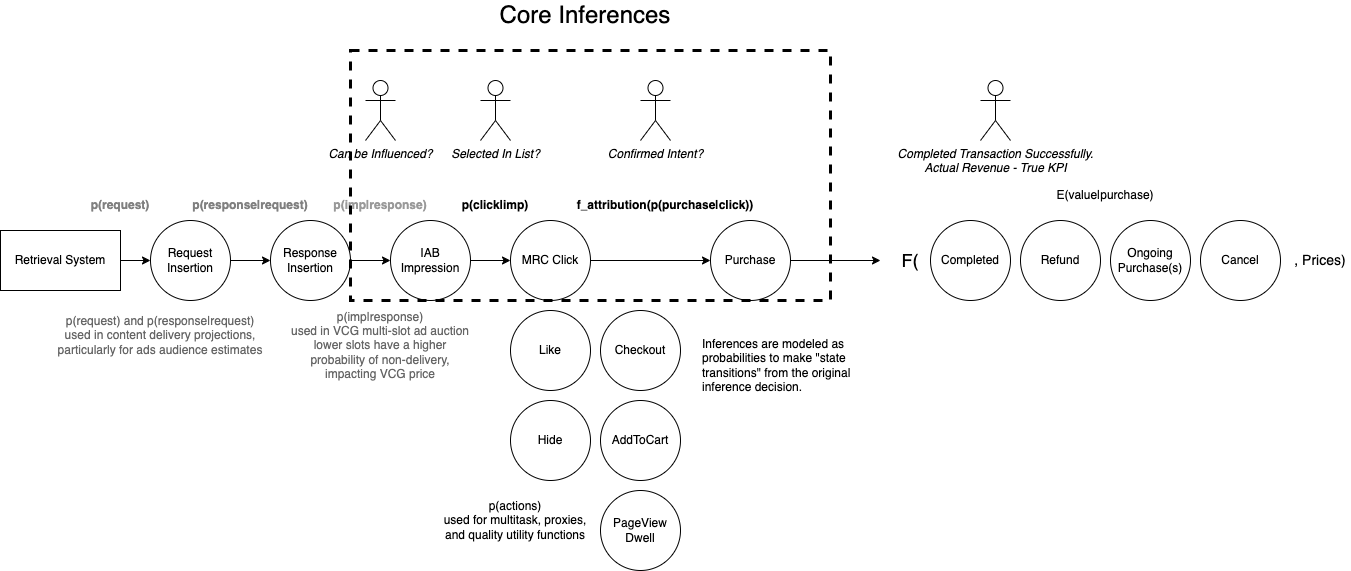
User State Transition Inference Graph
Promoted.ai uses a "user state transition model" for making calibrated inferences. A "calibrated" inference means that the sum of inferences equals the sum of the actual observations in expectation — for example, if the model predicts p(click|imp) = 10% for 1,000 insertions, then on average, the true click rate is 100/1000 or 10%. The correctness of the inference can be validated by comparing the sum of inferences with the actual predicted events. In the second-stage ranking, all insertions are assumed to be delivered at position "0" at inference time. The state transition model makes it easier to reason and validate complex chains of inferences when the underlying measurements are noisy and potentially unreliable or duplicated. Some event inferences are outside of the "core inference state transition" chain, but are still useful as features in quality models and as additional tasks to improve multi-task inference models. Note that this diagram is simplified: Promoted models the transition from an insertion or click to a purchase using an attribution model which may assign fractional credit to multiple insertions.
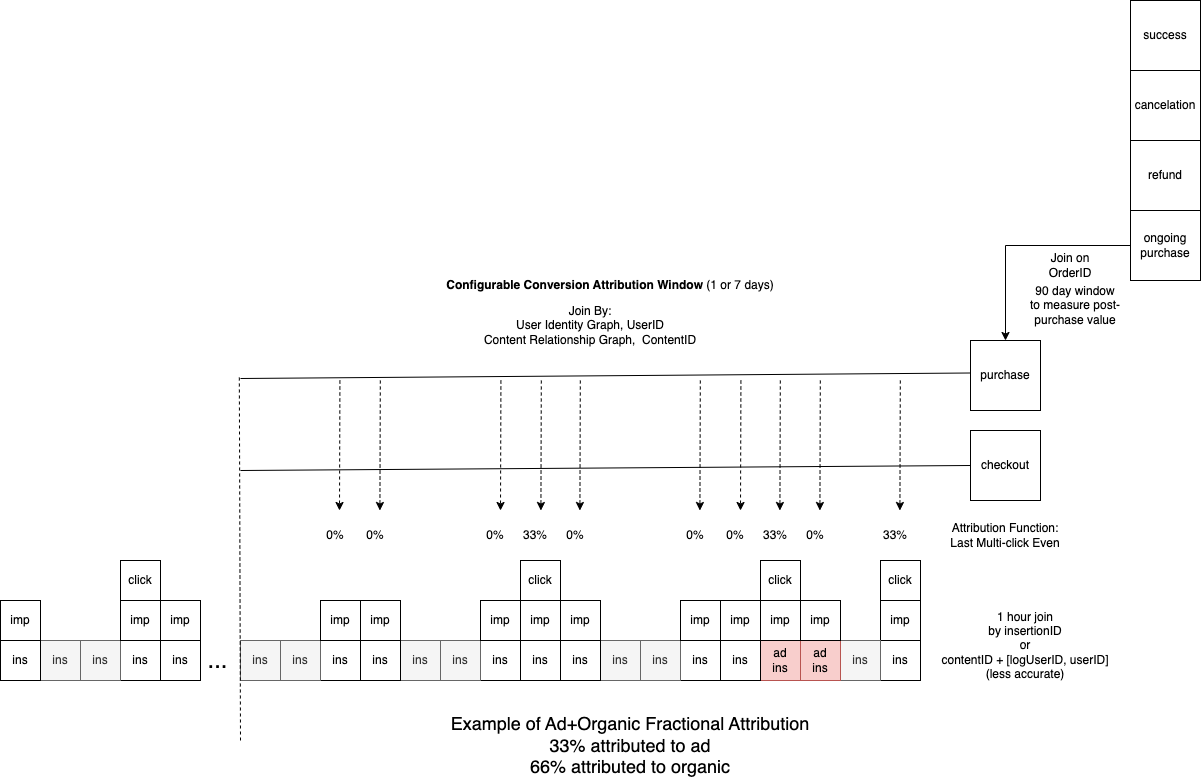
Click, Conversion, and Post-Purchase Joining and Attribution
Promoted.ai stream-joins Delivery logs like Request and Insertions with Metrics user events like impressions, clicks (navigates), checkouts, purchases, and post-purchase events to construct measurement attributed to delivery decisions used to construct training examples for machine learning and attributed (billable) ad metrics. Promoted uses multi-joining to assign fractional credit for conversion per a configurable attribution model to insertions. By default, Promoted uses 1-day multi-click even-attribution model but can support different causality models. Attribution uses a mixture of user and content IDs. Post-purchase events like cancelations, returns, subscriptions, and refunds are attributed to a purchase by order ID for a much longer window for use in modeling purchase value or negative post-booking experiences.
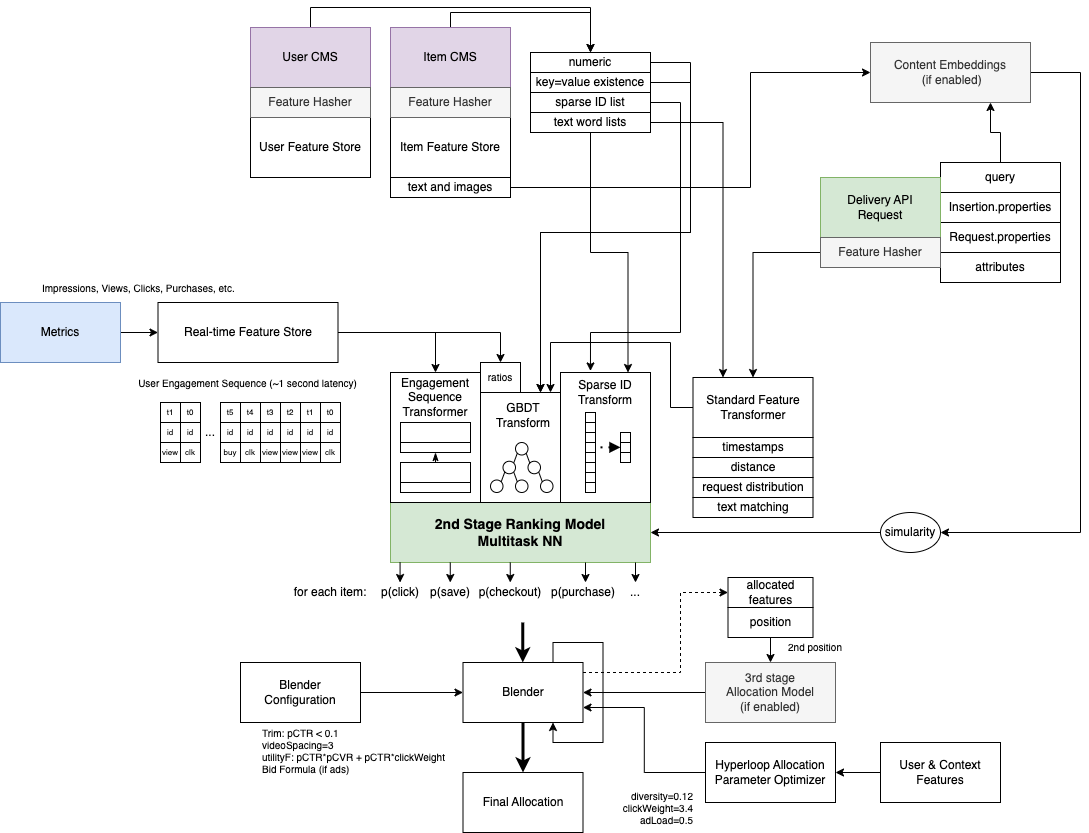
ML Feature Types at Inference Time
Delivery inference uses a variety of different feature types and feature stores in different formats and transformations to make predictions. Generally, Promoted uses all available information about the user, item, request, context, and time to predict engagement per listing and then assemble the optimal allocation while adhering to optimized allocation rules.
- Delivery API Request: Any feature can be passed on a Delivery API Request or Request Insertion as unstructured JSON. Delivery transforms this information for use in machine learning in real-time in a similar way as Item and User Feature Stores are transformed. Such features could be information from other ML systems (e.g., retrieval score), which is one way of implementing model stacking. Delivery also accepts common properties like "query" and other common attributes. Both dense and sparse features may be generated from a Delivery API Request.
- Item and User Feature Stores: Delivery fetches a page of "largely stable" ML features per Item or User ID which have been pre-transformed and processed for efficiency from unstructured JSON. The underlying Content Management System (CMS) preserves past versions of features with the assumption that these features are not updated continuously (less than several hundred times per day, or more commonly, at most once per day). Both dense and sparse features may be generated from a Delivery API Request.
- Real-time Feature Store: Some ML features continuously update because they represent the live traffic pattern of users and items. Such features include annotated user engagement sequences (similar to Pinterest) with availability latency of about 1 second and item/user/context engagement counts with availability latencies of a few seconds. The real-time feature store is implemented using Flink, RocksDB, and Redis. Counts are used directly as ML features or to compute ratios (e.g., 1-day click count / 1-day impression count) as dense features. Sequences are processed using a transformer layer.
- Content Embeddings: Some types of media (text, images, videos, audio) are not appropriate for direct use in ML and need to be transformed into compressed numerical representations. This (optional) service computes embeddings for media attached to items in the Item CMS and for queries and may compute similarity metrics as additional ML features.
- String and Text Processing: Sometimes, you just want simple text-matching search. We implement many common text matching algorithms including the longest common sequence and substring between all free text in items and contexts like titles, queries, descriptions, filters, tags, etc. All such text-matching scores become features for ML.
- Request Distributions: For some important features like average CTR, price, and distance, we compute the relative rank of that feature in comparison to all other items ranked (e.g., the cheapest or closest item available in this page compared to other items). This is like a very simple third-stage ranker that is easy and cheap to compute.
- Special Transformers: Distance, time-to-now, radians... we have an agglomeration of automated feature transformations that generate domain-specific ML features by common sense keyword matching and by configuration. We are always adding more of these as we add new types of customers.
- Blender and Hyper-parameters: Allocation is controlled by a dynamic configuration language that itself is controlled by customizable hyper-parameters that can be continuously optimized. For example: the utility function or insertion or blending rules are defined and optimized using the blender system in coordination with the 3rd stage ranker.
Multi-stage Delivery System Diagram
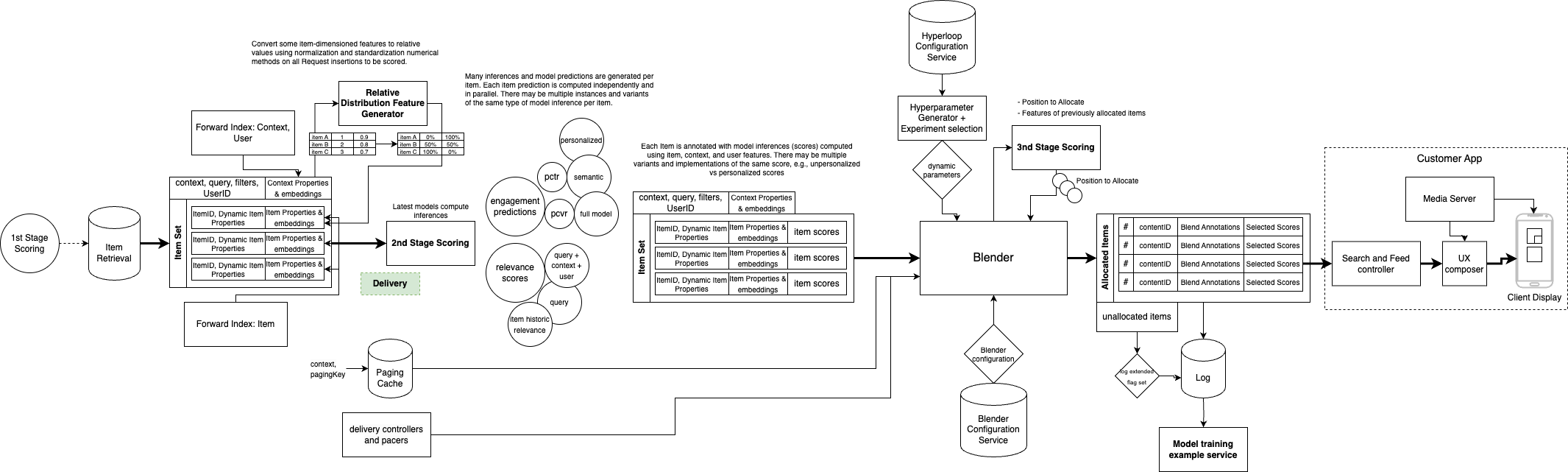
This is an alternative multi-stage system diagram. The diagram emphasizes that the output of second-stage "scoring" is a collection of inferences that are used as feature inputs to Blender models to compose the optimal allocation. This is in contrast to many "ranking" system designs which assume "second-stage ranking" produces a single "quality score" for ranking use. This diagram further elaborates that the response includes annotations and samples from both delivered and unallocated items for training example generation from logs.
Updated 6 months ago